
Timeline of Oracle v. Google and the docket files
Issue: whether Oracle can claim a copyright on Java APIs and, if so, whether Google infringes these copyrights.

Issue: whether Oracle can claim a copyright on Java APIs and, if so, whether Google infringes these copyrights.
原文载:
http://www.zdnet.com.tw/news/software/0,2000085678,20149350,00.htm
Nortel(北電)表示它正計畫將所有剩餘的專利與應用,以9億美元的價格賣給Google,除非有更高的出價者搶標。
透過此舉,Google將可取得大約6,000項涵蓋無線與數位通訊技術的專利。目前最大的問題是Google打算如何處理這些專利。短期的可能是部分的專利將會使用在Android之上—以及抵禦一些廠商如甲骨文的控告。
Google在部落格的文章中指出:
公司在對抗這類訴訟的最佳防衛策略是擁有強大的專利智庫,它將有助於維持開發新產品與服務的自由。Google是一家相對較年輕的公司,雖然我們擁有越來越多的專利,但我們的許多競爭者由於公司歷史更悠久,專利也更多。
Google可望從Nortel取得大量的專利,後者因為破產而將公司拆解出售。Google將可取得無線、4G、數據網路、光纖、語音、半導體與其他電訊領域的專利。
Nortel則在聲明中指出:
這些非常完整的專利智庫幾乎包含了電訊的所有層面,另外還包含了其他市場,包括網際網路搜尋與社交網路。
Nortel表示,之前曾經有許多家廠商參與多次競標。Google與Nortel已經達成所謂的「假馬資產銷售(stalking horse asset sale)」,其他符合資格的競標者仍可出價高於該搜尋引擎龍頭的價格來搶標。
The game of “Spoting the Difference" starts again!
Google’s ICP license renewed. See the captured today’s Google.cn web page below (left), and compare it with the page in last week (right).
| Google.cn on 9 July 2010: |
Google.cn on 4 July 2010: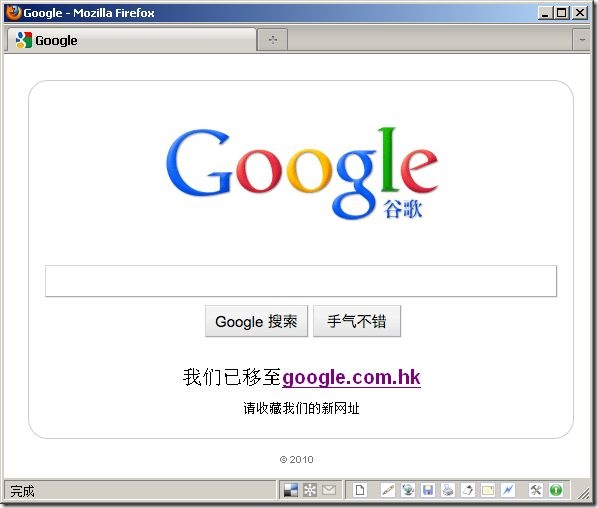 |
Exactly as what I predicted, Google is trying to make Google.cn being a non-search engine website. It now places "Music", "Translation" and "Shopping" at the web page. These are what Google wishes to keep on running in China. While the search engine service of Google.cn is replaced by a link to google.com.hk. Legally speaking, Google.cn is not providing search engine service currently. It is merely a link to another website. Just like the links added in any of our own web posts.
From Google.cn, to G.cn, to Chinese name Guge, this Internet giant tried to fit its size and pose to the bottle of censorship, while it still can not afford the conflict of the values. In 2009, it has been blocked from access, humiliated for spreading porn and accused for copyright infringement. Finally, Google expressed its value in a direct, as well as not Chinese, way.
When I heard this news yesterday, the first thing what I did was to save the page of Google.cn. It may be dead soon.

Following a tweet, people gathered and present flowers to Google Beijing office (click here for more, and the latest report is: along with flowers and candles, a book 1984 by George orwell joined the gifts for sacrifice):
Twitter is blocked in China, but yesterday the Chinese twitters made tag #GoogleCN climbed to the top ten of twitter’s keywords. It is a bit touching, and a bit hopeful – A profitable, foreign company get this means filtering and block still not make Chinese people (at least some of them) losing their eyesight and judgment to what is good and what is bad.
 There is a big chain restaurant company who named itself Eatool. Based in Amilina (a country allowing people eat almost everything except small chicken), Eatool provides delicious meats, including pork, beef and adult chicken. At the same time, it also sells dishware and other stuffs in each of its restaurants.
There is a big chain restaurant company who named itself Eatool. Based in Amilina (a country allowing people eat almost everything except small chicken), Eatool provides delicious meats, including pork, beef and adult chicken. At the same time, it also sells dishware and other stuffs in each of its restaurants.
I.
Few years ago, Eatool opened a new restaurant in Cinet, a country where the king forbid selling pork, as well as chicken.
Personally, Eatool’s boss loves pork, but he knows that selling pork in their Cinet restaurant means shut down the business including the dishware. So they hired Cinet people run the restaurant in Cinet, and restricted themselves from selling pork. At the same time, Eatool sells dishware to Cinetizens.
Eatool是一间大型的连锁餐饮集团。总部在阿米利亚(一个除了小鸡仔之外什么食品都允许吃的国家)。Eatool提供丰富多彩的菜式,有牛肉的、猪肉的、鸡肉的,很受人们的欢迎,分店开遍了世界。除了餐饮业外,Eatool的业务还拓展至餐具、厨房用品等等很多方面。
一
几年前,Eatool 在西纳开了一家分店。西纳是一个王国的名字。在这个国家里,国王禁止吃猪肉,也禁止吃鸡肉——不管是成年鸡还是小鸡的肉。
Eatool的老板自己是很喜欢吃猪肉的,但他知道,在西纳的分店里卖猪肉就意味着关张大吉,连厨具都卖不成。所以,Eatool在西纳的分店里雇用了西纳本地人,让本地人来打理店面,不卖任何含有猪肉的菜式,同时销售生产于阿米利亚的厨具。
在阿米利亚,Eatool的作法遭到了美食家们的批评:“咋能这样委屈自己呢?你应该在西纳卖有猪肉的大餐啊,排骨、火腿、还有猪颈肉!这是你的招牌菜!”
shizhao兄在我另一篇日志下问一个非常经典的问题,因为我的博客程序不支持评论的RSS输出,而这个问题本身的确非常有意思,所以把回复粘到这里。
shizhao[2009-12-04 02:16 PM ]说:
As an Interent application or online service, "Google Books" may not necessarily be found infringement.
But, Google would be held infringement liability if it really scanned Chinese books without authors’ consents.
First of all, I am talking about Chinese copyright Law. As for whether the same act would be held infringement in the US courts, I don’t know. I don’t know because once the Google Book Settlement is approved by judge, the case will be dismissed without ruling. Even if the settlement were not approved, and even if the case were finally ruled favoring Google, it would merely be a US judgement binding in the US, not necessarily binding in China. In other words, so long as the case is in Chinese courts’ jurisdiction, Chinese courts shall, according to Chinese copyrigh law, make their onw decisions no matter what the US court’s ruling is. This is a crutial common sence, but I doubt many people may forget it, because for a long time, I see too many comments to Chinese cases according to US laws.
Second, the only relationship between the US court’s ruling and China is: if China thinks a US binding judgment or the approval of settlement violate TRIPS, China may file the case to the WTO.
Third, back to the dispute between Chinese writers and Google, for the forgivable exploitation of the copyrighted works, Chinese copyright law is following the European mode of "limitations to coyright" but not the US concept of "fair use". Therefore, unless a non-liability provision has been provided explicitly, the conduct will be judged infringement once such conduct is regulated in Art. 10 of Chinese Copyright Law as the content of copyright. Until now, China only allows the search engines to store the content in other websites automatically. A conduct of scanning the books, from the first pege to the last, from the first line of each shelf to the last line, constitutes infringement definitely (unless the conductor is public library).
Fourth, Google’s self-limitation of accessing to the full-text of the scanned books is another story. The infringement has been established soon after scanning and storing books in its servers.
Last but not less importantly, this is a legal and positivist analysis. Not a value criticism. I am not saying that Google Books is a good/bad thing hereby. I am also not saying that one should not look at the case and the whole set of the current law critically. On the contrary, the real criticism should be based the fact on which some obvious good thing is hindered by the existing law, or some obvious bad thing is permitted by the existing law.
今天听说某人被送到医院急诊,于是打电话给他老婆及陪同去医院的朋友询问情况。电话拨过去后,传来一段被门夹到尾巴后挤出来的声音:
“对不起,您所拨打的用户无法接通,请稍候再拨——Shorty, the lumbar you are dying cannot be switched now, please die later”。
这种提示音最让人挫败的地方在于,你不知道那个lumbar到底是自己关了机还是掉进厕所被陶瓷马桶屏了蔽,而且你完全无法预计什么时候它会恢复正常,如果你和我一样着急的话,就只能一次又一次地die。
请先看这个新闻:澳大利亚政府限制Google Map显示“野火地图服务”
自2月8日上线后,GoogleMap所提供的野火监看服务,已有超过100万人次浏览。Google澳洲工程主任AlanNoble表示,得知澳洲消 防局 (CommonwealthFireAuthority,简称CFA)已无力维持其在线野火资料的更新,Google工程师决定伸出援手,在 GoogleMap提供即时地图、位置和野火强度等信息,并取得CFA同意。 但Google欲向维多利亚省永续环境部索取公有土地的火灾资料时,竟遭到拒绝,导致工程人员无法制作这部分的地图。根据Noble的说法,此事应归咎于Crown著作权法条。此规定将所有政府产生资讯的著作权,全数归于政府,防止未经明确许可的使用……
接下来是我的:
在CnBeta.com上看到谷歌音乐搜索上线的消息。地址是:http://g.cn/music,在中国内地的访问者应当可以见到类似下面的页面:
根据CnBeta的报道,和其他音乐搜索最大的区别是:谷歌音乐搜索搜索到的都是经过唱片公司授权的正版音乐。在我订阅的财经新闻中,也提到Google是在与音乐公司持续数月的谈判后,才在中国内地推出这个免费的音乐搜索服务的。我试了一下,上述谷歌音乐搜索的地址在香港无法访问,返回的页面非常简单,就一句话。截图如下:


{kind=link}
{kind=link}
这是为什么?
[update 2009-12-6] LJR兄提醒我说信息网络传播权保护条例第21条是不管“搜索引擎扫描复制网页到自己的服务器”的行为的。我才发现自己一开始写这篇帖子的时候,脑子里把“网页快照”和“系统缓存”混在一起了。下面是修改后的帖子,绿色部分是新增加的,删除线部分是原来写的一些话。本文不得转载(因为你一转载就把删除线转载丢了,文章就乱套了)。
对网页的检索为什么不侵权?经济学上社会学意上的原因我这里不分析,而是说明法律上的原因:很简单,因为法律的规定。中国的《信息网络传播权保护条例》中将这种情况作为“对著作权的限制”排除在侵权之外了。条例颁布于2006年,颁布之前这种行为在中国侵权不侵权?我不知道,因为没有明确的法律规定将作品数字化是否是“复制”。好了,先把搜索网页的搜索引擎服务放在一边,转过头来分析谷歌图书搜索:这个和网页搜索又是不一样的:Google是将本来是实体的书本全文扫描后,再放到网站上,这已经完全不是条例第21条的范围。所以,无疑是侵权的。
归纳一下,为什么搜索网页不侵权,搜索图书就侵权?这个问题本身就有误解。法律并没有说提供搜索网页的服务不侵权。相反,至少在目前的中国法律体系中,为了提供搜索服务,而将网页整个地存储在服务器中也是侵权的。网页快照更是侵权的,只是这一服务对大家都有好处,并且搜索引擎提供了让网站决定自己是否被搜索、是否被快照的功能,所以没有人告。
因为法律对为了搜索网页的目的,将已经被他人数字化的作品进行自动的全文复制的行为提供了有严格条件限制的免责待遇。但无论如何,行为人自己将图书一本一本全文数字化并永久存储,以便自己提供内容搜索服务这个行为,与将他人数字化的网页存放在服务器中、随着他人网页的变化自动变化的情况是完全不同的,法律肯定没有为数字化图书的行为提供免责待遇,肯定属于侵权行为。————————————
[1] 《信息网络传播权保护条例》其实不只在讲作为“著作权”下位概念的“信息网络传播权”,而是在讲信息网络上的著作权。这后面的原因在于一个巨大的误解,讲出来就是一篇论文了。因为跟主题关系已经不大,这里不多说了。
[2] 即使我们在未来的著作权法改革中,从别的理由出发(比如公共图书馆的合理使用…可惜谷歌无论如何都不是图书馆,所以也轮不到它),认为可以将某些扫描图书并提供网上浏览的行为合法化,都还可以再讨论,但以适当引用这一条作为出发点——讲直接一点——完全不搭边。